
Enforcing Data Quality and Governance with Claude Code (part III)
From rules to enforcement: how the skills from Part II become a governance framework, an infrastructure cross-check, and a compounding knowledge system.

Quick Recap
In Part II, we set up the enablers that embed architectural knowledge into Claude Code for a data platform:
CLAUDE.md — the platform’s persistent memory: architecture rules, quality gates, and environment configuration loaded at every session start.
Pipeline creation skills — skills with frontmatter and supporting files (templates, examples, validation scripts) that encode the mandatory notebook structure, so every new pipeline starts compliant. Auto-loaded by Claude when it detects relevant work, or invoked explicitly with
/spark-notebook.Governance audit skills — user-invoked skills (
/validate-serving-layer,/audit-cache,/check-merge-keys) that verify existing code against the quality rules in seconds. Each usesallowed-toolsto restrict itself to read-only operations.Bundled skills —
/review,/batch,/loop, and/debugship with Claude Code and chain with custom skills for comprehensive governance workflows.
This post takes those enablers into production. We show how a representative set of six quality rules—illustrative rather than exhaustive—can be operationalized into an enforceable framework, how a dedicated skill cross-references Terraform and notebook code, what a complete Spark notebook looks like when generated by the skill, and how auto memory and agentic workflows compound the platform’s resilience over time.
01 · Data Quality and Governance Through Claude Code
The six quality rules from the platform architecture are not documentation — they become enforceable checks when embedded into the skills system. Each rule maps to a specific skill, a specific mechanism, and a specific moment in the development cycle:
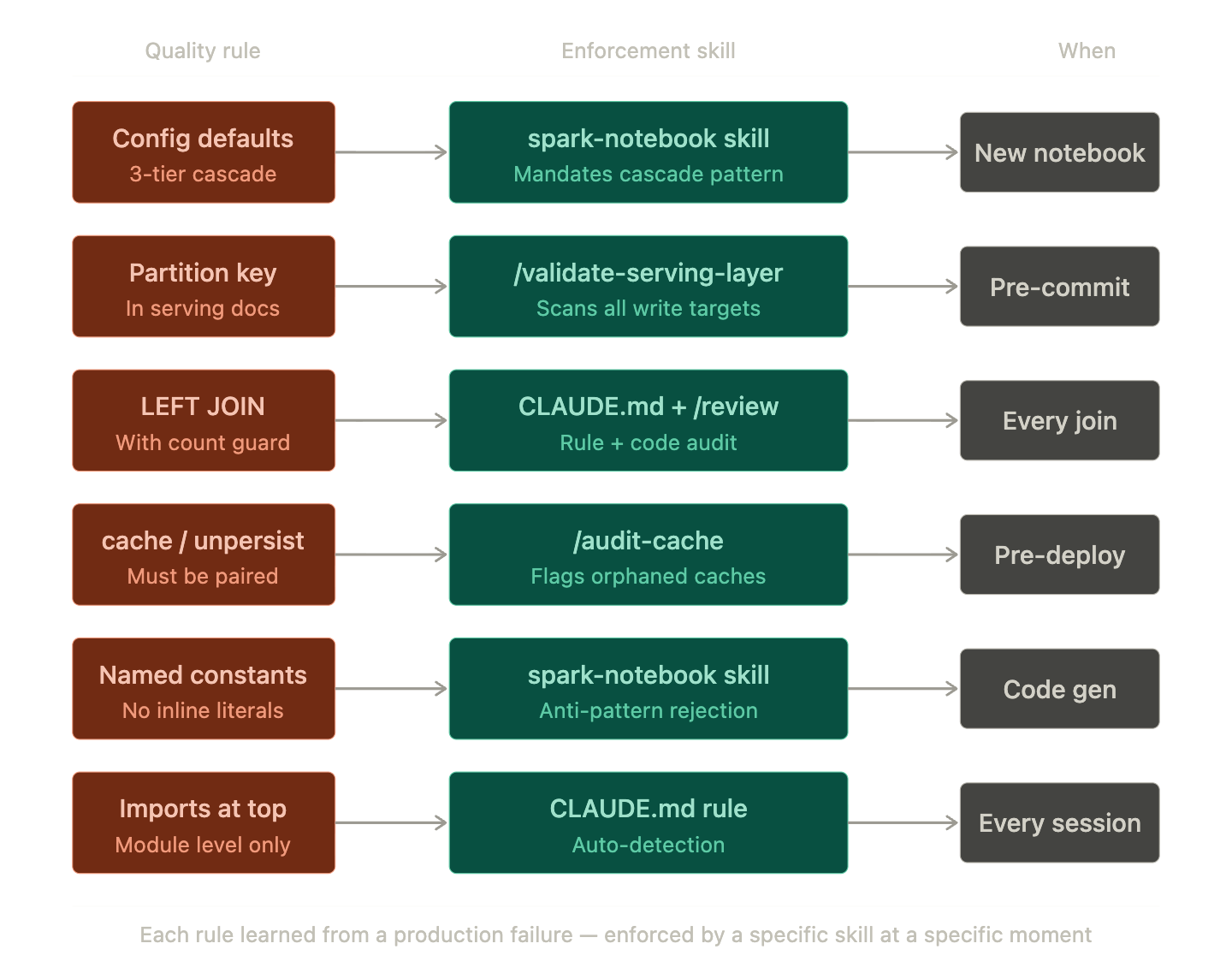
Notice the mix of enforcement types. Pipeline creation skills (like spark-notebook) prevent violations at generation time — the code is never wrong in the first place. Governance audit skills (like /validate-serving-layer and /audit-cache) verify existing code retroactively. And CLAUDE.md rules apply to every session regardless of which skill is active. The three layers overlap by design: if a creation skill misses something, an audit skill catches it; if both miss it, auto memory (Section 04) learns from the production failure and flags it next time.
The Governance Feedback Loop
When Claude Code detects a violation — an orphaned
cache()or a missing partition key — it does not just flag the problem. It explains why the rule exists (OOM on shared sessions, silent data loss in the serving layer) and suggests the exact fix. Over time, this trains the development team to internalize the rules, not just follow them. The tool becomes a teaching mechanism, not just a linting tool.
For domain-specific data quality, Claude Code validates incoming data patterns against documented thresholds. Coordinates outside valid bounding boxes, sensor readings outside physical ranges, alert classifications that must be computed consistently — all of these can be checked through a single audit skill that reads both the code and the validation rules documentation referenced via the context frontmatter field.
02 · Terraform — Infrastructure-to-Application Consistency
Infrastructure as Code is not just about provisioning. In a data platform, the Terraform definitions create the contract that application code must follow: container names, partition key paths, throughput settings, Key Vault policies. Claude Code helps enforce that contract through a dedicated cross-check skill.
# infra/modules/cosmos/main.tf
resource "azurerm_cosmosdb_account" "analytics" {
name = "dataplatform-${var.environment}-cosmos"
location = var.location
resource_group_name = var.resource_group_name
offer_type = "Standard"
kind = "GlobalDocumentDB"
consistency_policy {
consistency_level = "Session"
}
}
resource "azurerm_cosmosdb_sql_database" "analytics_db" {
name = "operational-analytics"
resource_group_name = var.resource_group_name
account_name = azurerm_cosmosdb_account.analytics.name
}
# One container per Gold-layer entity
resource "azurerm_cosmosdb_sql_container" "batch_kpis" {
name = "gold-batch-kpis"
resource_group_name = var.resource_group_name
account_name = azurerm_cosmosdb_account.analytics.name
database_name = azurerm_cosmosdb_sql_database.analytics_db.name
partition_key_paths = ["/partition_date"] # ← Must match notebook code
throughput = 400
}
# infra/modules/fabric/main.tf
resource "azurerm_fabric_capacity" "analytics" {
name = "dataplatform-${var.environment}"
resource_group_name = var.resource_group_name
location = var.location
sku {
name = "F4" # 4 CU ceiling — budget constraint
tier = "Fabric"
}
}
resource "azurerm_key_vault" "dataplatform" {
name = "kv-dataplatform-${var.environment}"
location = var.location
resource_group_name = var.resource_group_name
sku_name = "standard"
tenant_id = data.azurerm_client_config.current.tenant_id
purge_protection_enabled = true
}
This cross-boundary check is a natural fit for the skills system. A dedicated skill can auto-load the Terraform files via the context frontmatter field and cross-reference them against notebook write targets:
---
name: check-infra-consistency
description: >
Cross-references Terraform Cosmos DB container definitions against
notebook write targets. Detects partition key mismatches, missing
containers, and naming convention violations across infrastructure
and application code.
allowed-tools:
- Read
- Bash(grep:*)
- Bash(find:*)
context:
- infra/modules/cosmos/main.tf
- docs/table-schemas.md
---
# Check Infrastructure-to-Application Consistency
1. Parse all Cosmos container definitions in infra/modules/cosmos/
Extract: container name, partition_key_paths, database name
2. Search all notebooks for Cosmos write operations
Extract: target container name, partition key field in document
3. Cross-reference:
- Does every notebook container match a Terraform definition?
- Does every Terraform container have a notebook that writes to it?
- Do partition key paths match between infra and application code?
4. Check naming convention: "gold-{domain}-{entity}" in both layers
Report as:
| Container | In Terraform | In Notebooks | Partition Key Match | Naming OK |
Flag mismatches as CRITICAL — these cause silent data loss.
This is the kind of drift that traditional CI/CD pipelines do not cover because it spans two different codebases — infrastructure and application. A single skill bridges both.
03 · Spark Notebook — The Tail-Fetching Pattern in Practice
Here is a simplified version of the incremental replication pattern — the technique that bridges batch boundaries for gapless time series. This is what Claude Code generates when the /spark-notebook skill is invoked. The skill loads its supporting files — the cell skeleton from templates/notebook-template.py and the reference implementation from examples/silver-telemetry.py — then produces a notebook where every cell follows the mandatory structure, every config uses the 3-tier cascade, and every quality rule is applied automatically.
# notebooks/silver_incremental_telemetry.py
# ── Cell 1: Parameters ──
inj_config = "" # Injected by orchestrator, empty if standalone
environment = "dev"
# ── Cell 2: Configuration (3-tier cascade) ──
SOURCE_CONN = spark.conf.get(
"spark.dataplatform.source.connection",
"jdbc:postgresql://localhost:5432/telemetry" # dev default
)
SILVER_TABLE = "lakehouse.silver_incremental_telemetry"
BATCH_HOURS = 2
ACTIVE_THRESHOLD = 0.50 # Named constant — not inline literal
# ── Cell 3: Read Source + Tail Fetch ──
new_batch = spark.read.jdbc(
SOURCE_CONN, "telemetry_events",
properties={"fetchsize": "5000"}
).filter(f"event_time >= NOW() - INTERVAL '{BATCH_HOURS} hours'")
# Tail records bridge the previous batch boundary
from pyspark.sql import functions as F
from pyspark.sql.window import Window
existing = spark.read.format("delta").table(SILVER_TABLE)
tails = existing.groupBy("entity_id").agg(
F.max("event_time").alias("event_time")
)
tail_records = existing.join(tails, ["entity_id", "event_time"])
# ── Cell 4: Transform — LEAD window for end_time ──
combined = tail_records.unionByName(new_batch)
w = Window.partitionBy("entity_id").orderBy("event_time")
with_end = combined.withColumn(
"end_time", F.lead("event_time").over(w)
)
result = with_end.filter(
f"event_time >= NOW() - INTERVAL '{BATCH_HOURS} hours'"
).cache()
# ── Cell 5: Derive status from thresholds ──
result = result.withColumn("status",
F.when(F.col("connected") == False, F.lit("Disconnected"))
.when(F.col("idle_ratio") > ACTIVE_THRESHOLD, F.lit("Idle"))
.when(F.col("activity_metric") > 0, F.lit("Active"))
.otherwise(F.lit("Standby"))
)
# ── Cell 6: Write — Delta Lake MERGE ──
from delta.tables import DeltaTable
target = DeltaTable.forName(spark, SILVER_TABLE)
target.alias("t").merge(
result.alias("s"),
"t.entity_id = s.entity_id AND t.event_time = s.event_time"
).whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
# ── Cell 7: Cleanup ──
result.unpersist()
The pattern is generic. Replace entity_id with any entity key — asset IDs, device IDs, vehicle IDs, sensor IDs — and the tail-fetching technique works identically. The skill encodes the pattern; the developer provides the domain context. Claude Code handles the structural compliance.
After generating the notebook, you can run the skill’s validation script (scripts/validate-structure.sh) to confirm compliance, or invoke /audit-cache to verify that every cache() is paired with unpersist(). The creation skill and the audit skills form a closed loop.
04 · Auto Memory — Compounding Knowledge Across Sessions
Claude Code builds auto memory as it works — saving learnings like build commands, debugging insights, and project-specific patterns across sessions without explicit configuration. For a complex data platform, this creates a compounding knowledge loop:
How Memory Compounds
After debugging an OOM crash caused by an orphaned
cache()on constrained capacity, Claude Code saves that insight. Next time it creates or reviews a notebook, it proactively flags unmatched cache calls — not because of a rule in CLAUDE.md or a skill’s anti-pattern list, but because it learned from a real production failure.After encountering a serving-layer write that silently failed because of a missing partition key, that debugging pattern enters Claude’s working memory. It surfaces the warning before the same mistake happens again — across all developers on the project, not just the one who fixed it originally.
This is the strategic advantage that separates AI-assisted development from traditional tooling. A linter checks rules that were explicitly written. Skills encode patterns that were deliberately designed. Auto memory adds a third layer: patterns that were learned from experience. Every debugging session, every production incident, every code review feeds back into Claude Code’s project-specific understanding. The platform gets harder to break over time — not through more rules, but through accumulated operational wisdom.
The Three Layers of Protection
Think of it as defense in depth. Skills prevent known violations at generation time. Governance audit skills catch violations that slip through in existing code. Auto memory catches the violations that nobody thought to write a rule for yet — because they have not happened before. When a new failure mode occurs and gets debugged, it enters auto memory immediately, before anyone writes a new skill or updates CLAUDE.md. The formal rule comes later; the protection starts now.
05 · Agentic Workflows — Cross-Cutting Audits at Scale
The most powerful use of Claude Code for data platforms is not generating code — it is running cross-cutting audits that span infrastructure, application code, and documentation simultaneously. These workflows chain custom skills with bundled skills for comprehensive checks.
# Full governance audit — chains custom and bundled skills
$ claude -p "Run all governance checks:
1. /validate-serving-layer — partition keys
2. /audit-cache — orphaned caches
3. /check-merge-keys — MERGE key consistency
4. /check-infra-consistency — Terraform ↔ notebook alignment
Then run /review on any notebook flagged as NEEDS FIX.
Report all findings as a single markdown table with severity."
# Bulk audit across a domain using /batch
$ claude
> /batch "run /audit-cache on every notebook in notebooks/telemetry/"
# Pipe deployment logs for anomaly detection
$ tail -500 pipeline-run.log | claude -p "Analyze for:
- Failed MERGE operations
- Serving-layer write timeouts
- Unexpected null counts in partition columns
- Spark OOM warnings
Classify each as CRITICAL / WARNING / INFO"
# Recurring monitoring during deployments
$ claude
> /loop 30m "Check the latest pipeline run logs for
CRITICAL errors. Summarize and suggest a fix."
The workflow chains four custom governance skills, then feeds flagged notebooks into the bundled /review skill for general code quality analysis. The /batch bundled skill enables running any audit across multiple files in a single invocation — useful for domain-wide compliance checks before a release. The /loop skill acts as a lightweight monitoring layer during deployment windows, and the Unix-philosophy piping (tail | claude) integrates Claude Code into the same operational workflows that already exist in the terminal.
06 · The Full Development Stack
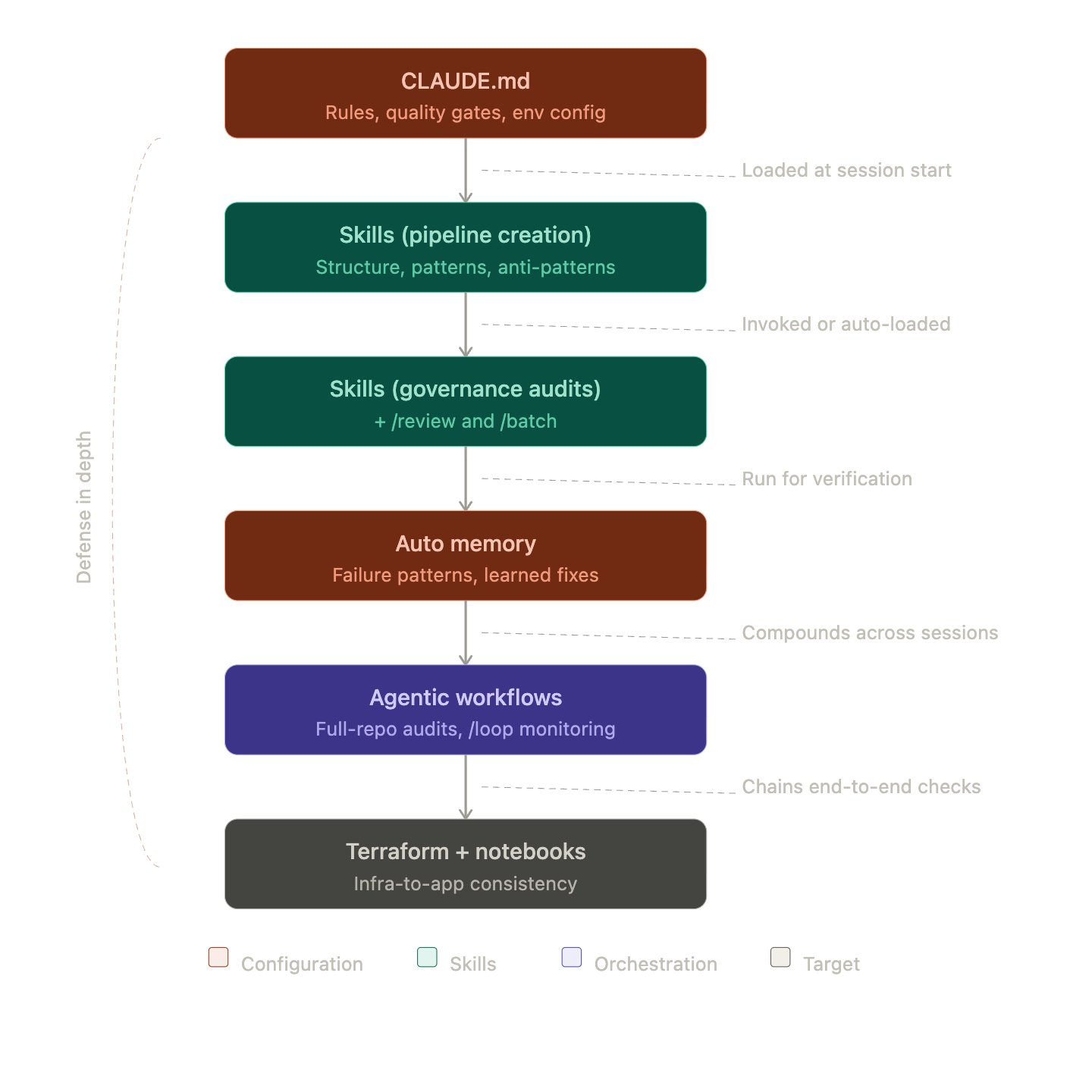
Each layer builds on the previous one. CLAUDE.md provides the architectural foundation. Pipeline creation skills encode the implementation patterns. Governance audit skills verify compliance — amplified by bundled skills like /review and /batch for reach. Auto memory retains the lessons from production. And agentic workflows tie everything together into a system that actively prevents regression — not just in code, but in the cross-cutting architectural decisions that make a data platform reliable.
07 · Key Takeaways
Claude Code is not a code generator — it is an architectural enforcement layer. For complex data platforms, the value is not in writing PySpark faster. It is in embedding foundational and reliable knowledge into the development workflow so that quality rules are enforced automatically, failure patterns are remembered across sessions, and cross-cutting checks run in seconds rather than hours.
CLAUDE.md is a routing table, not a knowledge dump. Keep it concise, encode the rules, and use progressive disclosure for deeper context. Under 60 lines is enough for production ready pipeline platform.
Pipeline creation skills prevent violations at generation time. Catching a missing partition key during code review costs hours. Preventing it with a skill that encodes the mandatory structure, supported by templates and examples, costs zero. Encode every repeatable pipeline pattern as a skill.
Governance audit skills make compliance auditable and repeatable. The /validate-serving-layer skill catches the exact failure mode that caused days of debugging — and it runs in seconds. Every hard-won lesson from production should become a skill. Use allowed-tools to keep audit skills read-only and context to auto-load reference documentation.
Auto memory creates a compounding advantage. Skills catch known patterns. Memory catches patterns that nobody thought to write a skill for yet. The more failures Claude Code sees, the harder the platform becomes to break.
Cross-boundary consistency is the hardest problem. Terraform container definitions, notebook partition keys, serving-layer document schemas, and documentation must all agree. A single skill with the right context fields bridges infrastructure and application code — catching drift that no single-tool CI/CD pipeline can detect.
The Series
Part I — How to Build a Real-Time Analytics Platform on a Constrained Budget.
Part III — Enforcing Data Quality and Governance with Claude Code. (You are here)
Claude Code · Terraform · PySpark · Delta Lake · Unified Skills · Data Governance · Auto Memory · Agentic Workflows · Platform Engineering
Disclaimer: Built from the ground up using documentation and diagrams from production-scale Medallion architectures. While Claude assisted in the structural organization of this post, all technical strategies and data-processing milestones are derived from my direct professional practice.