
How to Build a Real-Time Analytics Platform on a Constrained Budget (part I)
Architecture decisions, data governance patterns, and investment strategies for turning heterogeneous data streams into a unified intelligence layer — on Microsoft Fabric.

01 · The Architectural Challenge
Every data-intensive operation faces the same structural problem: the systems that generate data were not designed to talk to each other. Dispatch platforms export batch files on a X-hour cadence. Telemetry systems stream sensor readings every 10 minutes. GPS trackers emit continuous position data. Environmental sensors report for regulatory compliance. Operational databases accumulate millions of rows of time-series data.
Each source has its own format, cadence, latency requirements, and failure modes. The business, however, does not care about any of that. It needs a unified analytical layer that produces consistent KPIs, feeds real-time dashboards, and supports historical analysis — all on a compute budget that is not unlimited.
This is a pattern that repeats across industries: manufacturing, logistics, energy, mining, agriculture, insurance, financial, etc. The specific data sources change, but the architectural challenge is the same — how do you turn fragmented, heterogeneous data streams into a single source of truth without building an expensive monolith?
The Real Constraint
The hardest problem is not ingesting the data. It is maintaining consistency across all consumers. When a KPI is computed in a Spark notebook, displayed in a Power BI dashboard, and served through a REST API, all three must produce the same number. Business constants, exclusion rules, and threshold logic must be identical everywhere — and they must survive team changes, late-arriving data, and pipeline failures.
02 · Architecture Strategy: The Medallion Pattern
The medallion architecture is not new. But the value is not in the pattern itself — it is in the discipline of separating concerns cleanly. Each layer has a specific responsibility, and no layer is allowed to bypass the one before it.
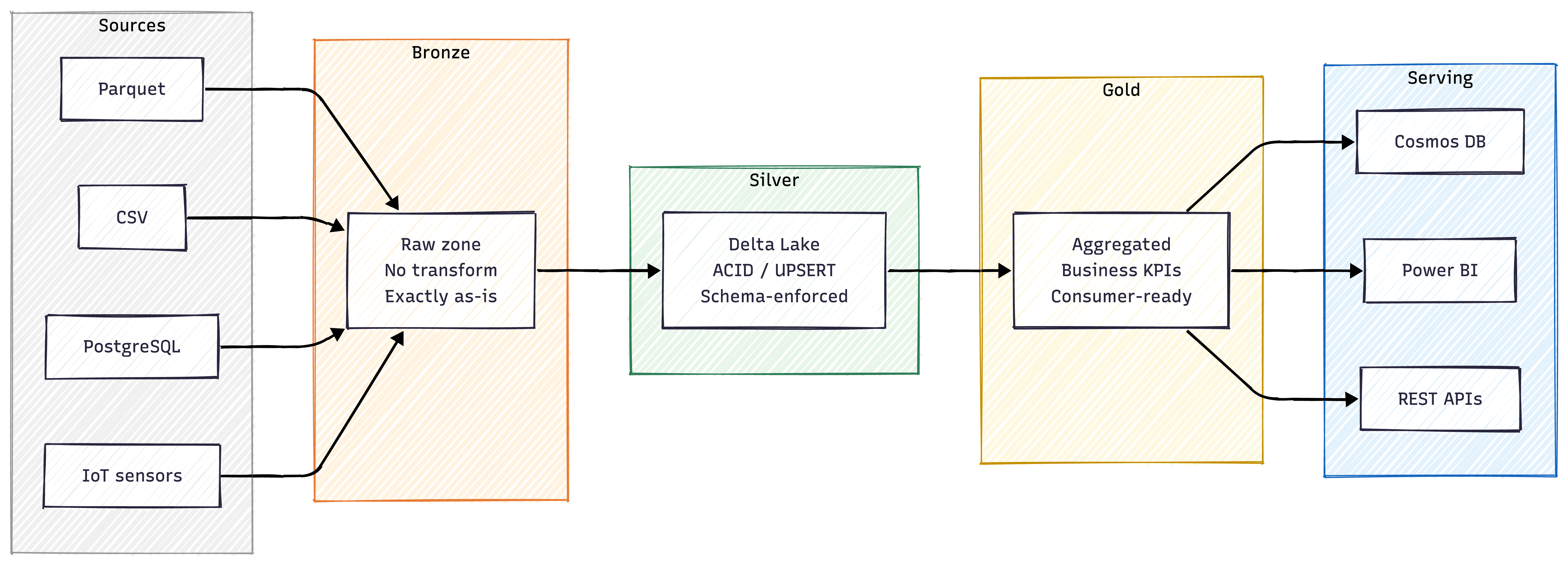
Bronze is a pure landing zone. Data arrives exactly as-is — no transformations, no cleaning, no schema enforcement. This is the safety net: if anything goes wrong downstream, the raw data is always available for replay.
Silver is where trust is established. Schema enforcement, data type validation, deduplication, and ACID-compliant writes (via Delta Lake MERGE) happen here. Every record that enters Silver has passed a set of validation rules. This is the layer where domain-specific checks — geographic bounding boxes, valid ranges, referential integrity — are applied at ingestion time, not after the fact.
Gold is the business layer. Aggregations, enrichment with dimension tables, KPI computation, and industry-standard metrics are calculated here. This is the only layer that consumers should ever query directly.
Serving is the delivery mechanism. Cosmos DB provides sub-second latency for real-time dashboards. Power BI connects directly to Gold tables for historical reporting. REST APIs expose KPIs to external systems.
Why This Matters Strategically
The medallion pattern is fundamentally a risk management architecture. Each layer isolates a different kind of failure. Bronze absorbs source-system instability. Silver prevents bad data from contaminating analytics. Gold ensures business logic is computed once and shared everywhere. When something breaks — and in a 24/7 operation, it will — the blast radius is contained.
03 · Three Ingestion Patterns for Different Data Behaviors
Not all data behaves the same way. A shift report that arrives every 12 hours requires a fundamentally different ingestion strategy than a sensor reading that arrives every 10 minutes, or a database that accumulates millions of rows of time-series data. Trying to force all three through the same pipeline creates fragile, overloaded systems.
I want to share three distinct ingestion patterns proved by my self in large data solutions, each designed for a specific data behavior:
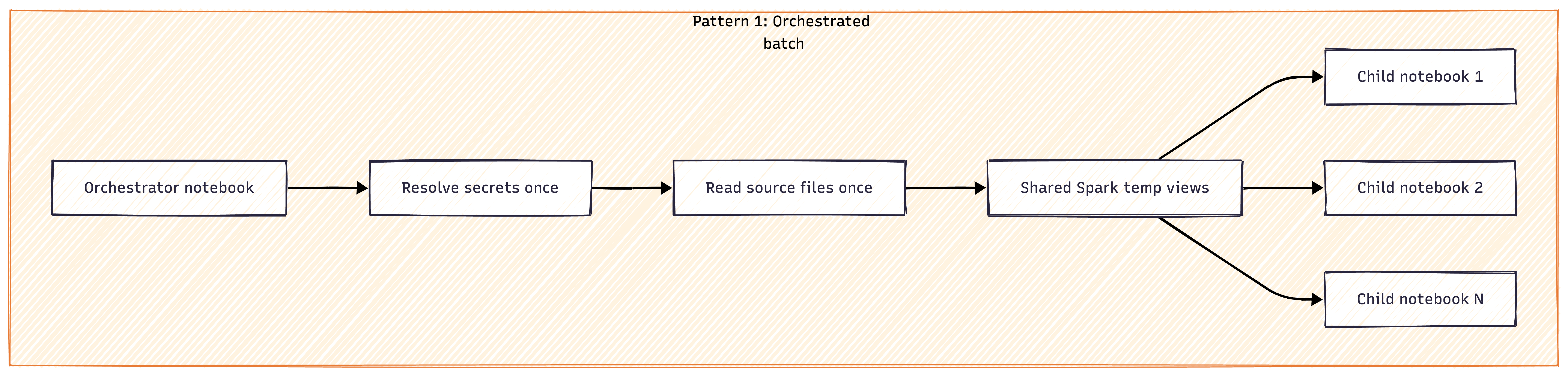
Pattern 1 — Orchestrated Batch
For periodic, structured exports: an orchestrator notebook acts as the single entry point. It resolves all secrets once, reads all source files once into shared Spark temp views, then runs child notebooks sequentially within a single Spark session. This reduces cold start overhead by approximately 60% and guarantees that all child notebooks consume identical input data. Each child can still run independently in development mode by falling back to its own file discovery logic.
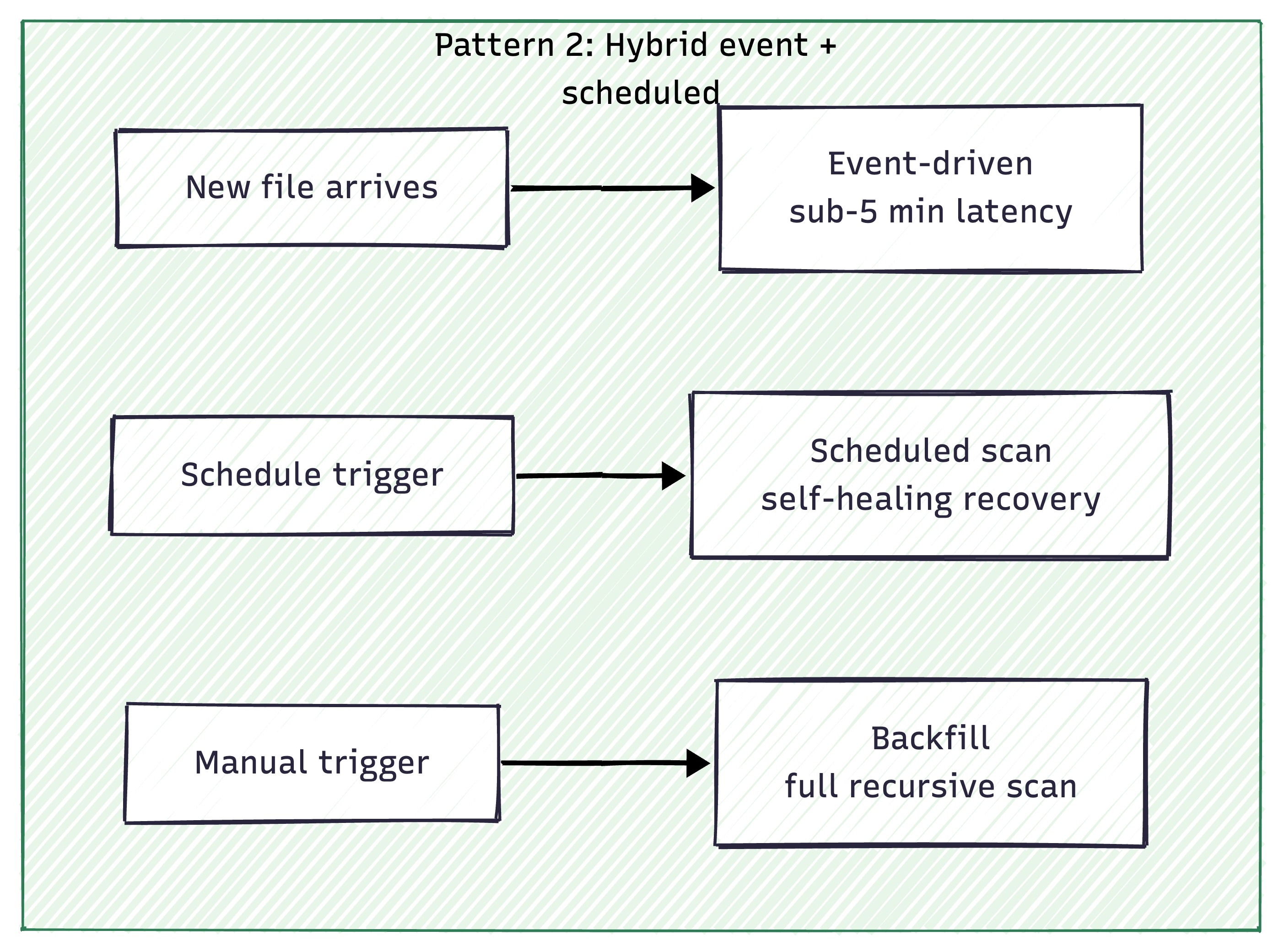
Pattern 2 — Hybrid Event-Driven + Scheduled
For multiple independent streams with different formats and frequencies: each stream gets its own isolated notebook with three execution modes. Event-driven (triggered by new files, sub-5-minute latency) handles 90% of normal operations. Scheduled (every 1–4 hours, using time-based path generation instead of recursive directory listing) provides self-healing recovery. Backfill (full recursive scan, manual trigger) supports initial loads. The scheduled mode uses generated path patterns rather than listing thousands of folders, so performance stays constant regardless of total data volume.
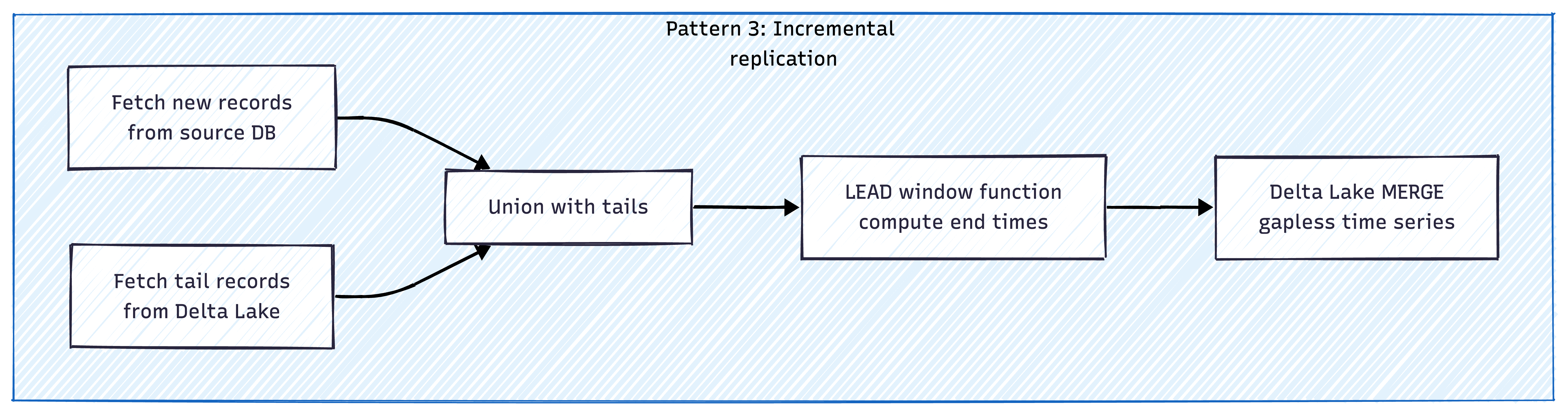
Pattern 3 — Incremental Replication with Tail Fetching
For continuously growing source databases: the pipeline fetches new records from the source, but also retrieves the tail record per entity from the existing Delta Lake table. These tails are unioned with the new batch before applying window functions (LEAD) to compute derived fields like end times. This bridges batch boundaries without reprocessing historical data, keeping each run’s scope minimal while producing a complete, gapless time series.
The key insight: these three patterns are transferable. They are not specific to any industry or vendor. An orchestrated batch pattern works the same way whether it processes manufacturing production runs or logistics delivery cycles. The hybrid event/scheduled pattern applies anywhere you have multiple independent data sources with different cadences. And tail fetching solves the incremental time-series problem regardless of the source database technology.
04 · Data Governance as Engineering Discipline
Governance in a real-time analytics platform cannot be a separate workstream. It has to be embedded in every write operation, every pipeline structure, and every deployment. Here is the framework that makes that practical:
Idempotency everywhere. Every write operation uses Delta Lake MERGE (UPSERT). Re-running any pipeline for any time window produces identical results without creating duplicates. When pipelines run on schedules, they will occasionally overlap, retry, or be manually re-triggered. Every write must be safe to repeat. This is the foundation of data trust in any batch or hybrid processing system.
Validation at ingestion, not downstream. Bad data that enters the Silver layer will propagate to every consumer. Geographic coordinates outside valid ranges are rejected on arrival. Geometry data is validated and centroids are extracted during ingestion. Alert thresholds are computed at write time with classification logic that cannot be manually overridden. The principle: if a record passes Silver, it is trustworthy.
Configuration hierarchy, not hardcoded values. All pipelines use a 3-tier cascade: Key Vault → Spark Config → Default Value. This supports multiple environments (dev/UAT/prod) without code changes and makes standalone notebook development possible without infrastructure access.
Six Quality Rules (at least) — Enforced Repo-Wide
These are not guidelines. They are deployment blockers:
Every environment config must have a default value.
Every document in the serving layer must carry its partition key.
All fact-to-dimension joins must be LEFT joins with count guards (depends on use case).
Every
cache()must be paired withunpersist()to prevent memory exhaustion on shared sessions.Named constants replace hardcoded literals everywhere.
Imports stay at the top of each module.
Each rule was learned from a production failure — not derived from theoretical best practices.
Documentation as engineering. Every code change requires a documentation update in the same commit. User-facing documentation must consider all the roles involved (Data engineers don’t speak data scientists’ language). Technical context files include mandatory checklists. Incomplete documentation equals incomplete work — not a nice-to-have that gets deferred.
05 · Budget Strategy: Running Pipelines on Minimal Compute
Architecture discussions often ignore the budget constraint. But the compute budget is the most powerful forcing function for good engineering. When you have unlimited resources, you can afford sloppy scheduling, redundant processing, and unoptimized pipelines. When you have a strict ceiling, every design decision matters.
For example if platform runs on a Fabric F4 capacity — one of the smallest SKUs available — with a ceiling of 4 Capacity Units. The entire scheduling strategy should be designed around staying within that limit.
The budget constraint is not a limitation — it is a design principle. It forces incremental processing (no full table reprocessing), shared Spark sessions (no redundant cold starts), and staggered scheduling (no overlapping compute bursts). These same patterns reduce cost at any scale, not just on an F4.
06 · Investment Strategy: CAPEX vs. OPEX in Modern Data Platforms
The traditional approach to data infrastructure treats it as a capital expenditure: buy servers, license software, build a data center, amortize over 3–5 years. This model has a fundamental flaw for analytics platforms — you are locking in capacity before you know what the platform needs to do.
Cloud-native, consumption-based platforms flip this model. The entire compute cost becomes OPEX — adjustable month to month, tied to actual usage rather than projected capacity. This has three strategic implications:
1. Prove Value Before Scaling
A small-capacity SKU costs a fraction of what traditional on-premise infrastructure requires. The platform can run in production, serve real dashboards, and demonstrate measurable ROI — all before a single scaling decision needs to be made. Investment follows validated results, not projected ones.
2. Granular Scaling, Not Step-Function Upgrades
Scaling from F4 to F8, F16, or F64 is a configuration change, not a procurement cycle. More importantly, the architecture is designed so that scaling does not require re-engineering. Staggered scheduling works the same way at any capacity. The orchestrator pattern, incremental processing, and tail fetching all produce constant-scope workloads regardless of data growth. The platform scales by adding capacity, not by rewriting pipelines.
3. Reversible Decisions
If a processing domain turns out to deliver less value than expected, its pipelines can be decommissioned and the capacity reclaimed immediately. With CAPEX infrastructure, sunk costs create pressure to keep using systems that have outlived their usefulness. With OPEX, every component must continuously justify its compute consumption.
This does not mean CAPEX has no role. For extremely stable, high-volume workloads where utilization is predictable, reserved capacity or committed-use discounts can reduce per-unit costs significantly. The strategic approach is to start OPEX, prove value, then selectively convert proven workloads to reserved capacity as their patterns stabilize. This minimizes risk at every stage.
07 · Scalability Path and ROI
This architecture was designed with explicit scalability mechanisms — patterns that support growth without requiring re-architecture:
Staggered scheduling absorbs new pipelines. Adding new data streams does not require more compute — just more precise time-slot management. The same capacity budget can serve additional pipelines by adjusting offsets and frequency windows.
The orchestrator pattern reduces marginal cost. Adding a new analytical notebook to an existing processing domain requires minimal incremental compute, because secrets, file reads, and Spark sessions are already shared. The overhead per notebook decreases as the domain grows.
Incremental processing keeps costs constant. Tail fetching and Delta Lake MERGE ensure that each run processes only new and updated records. Whether the historical table holds 1 million or 50 million rows, the per-cycle cost stays the same.
The medallion pattern supports new consumers without new processing. Once data reaches Gold, any number of serving endpoints — new dashboards, new APIs, new reporting tools — can consume it without touching the processing pipelines. The marginal cost of a new consumer is nearly zero.
The ROI Equation
The return on a real-time analytics platform is not in the infrastructure — it is in the decisions the infrastructure enables. When KPIs are computed consistently and served in near real-time, the business can act on operational signals faster: identifying underperforming assets, reducing unnecessary maintenance cycles, optimizing resource allocation. In capital-intensive industries, even a small percentage improvement in asset utilization can pay for the entire platform many times over. The architecture’s job is to make those decisions trustworthy, fast, and affordable.
08 · Key Takeaways
Separate concerns cleanly. The medallion pattern is not a buzzword — it is a risk management architecture. Each layer absorbs a different failure mode. Bronze absorbs source instability, Silver enforces trust, Gold computes business logic once, and the serving layer delivers it everywhere.
Match ingestion patterns to data behavior. Orchestrated batch, hybrid event/scheduled, and incremental replication with tail fetching are three distinct patterns for three distinct data behaviors. Forcing one pattern onto all data sources creates fragility.
Embed governance in the pipeline, not beside it. Idempotent writes, validation at ingestion, and enforced quality rules are not polish added after the platform works — they are the reason the platform works. Without them, every new pipeline becomes a liability.
Use the budget as a design principle. Constraints force better engineering. Staggered scheduling, shared sessions, and incremental processing are not compromises — they are patterns that reduce cost at any scale.
Start OPEX, prove value, then optimize. Cloud-native consumption models eliminate the need to justify large upfront investments. Prove the platform delivers measurable results on minimal compute, then scale with confidence.
Invest in transferable patterns, not vendor lock-in. The orchestrator pattern, tail fetching, hybrid ingestion, and the medallion architecture work on Fabric, Databricks, Snowflake, or any modern lakehouse platform. The engineering discipline is the asset — the vendor is the vehicle.
Medallion Architecture · Data Governance · CAPEX/OPEX · Delta Lake · Microsoft Fabric Apache Spark · Cosmos DB · Incremental ETL · Platform Strategy · Budget Optimization
Disclaimer: Built from the ground up using documentation and diagrams from production-scale Medallion architectures. While Claude assisted in the structural organization of this post, all technical strategies and data-processing milestones are derived from my direct professional practice.