
Usando IA para desafiar mis propias hipótesis
Creé un swarm de agentes que no construye tu business case para darte la razón, sino para llevarte la contraria.

La primera vez que le pedí a un LLM que me armara el business case de una idea, salió hermoso. Narrativa de crecimiento, TAM, unit economics, un moat que sonaba sólido. Lo leí dos veces y me sentí brillante. Después me di cuenta de algo incómodo: la herramienta no había validado nada. Me había devuelto, con mejor redacción, exactamente lo que yo quería escuchar (como suele pasar).
Y ahí está el problema de fondo con cómo casi todos usamos IA hoy: la usamos para confirmar. “Dime si mi idea es buena.” La IA, entrenada para ser útil y agradable, te dice que sí. Es el peor sparring posible — uno que te deja ganar.
Así que armé el experimento opuesto. En vez de un agente que valida, un swarm que desafía. La hipótesis era simple: si pongo a la IA a destruir mi caso en lugar de adornarlo, lo que sobreviva va a ser mucho más defendible. Spoiler: la hipótesis se sostuvo — pero no por la razón que yo pensaba, epic!.
El experimento
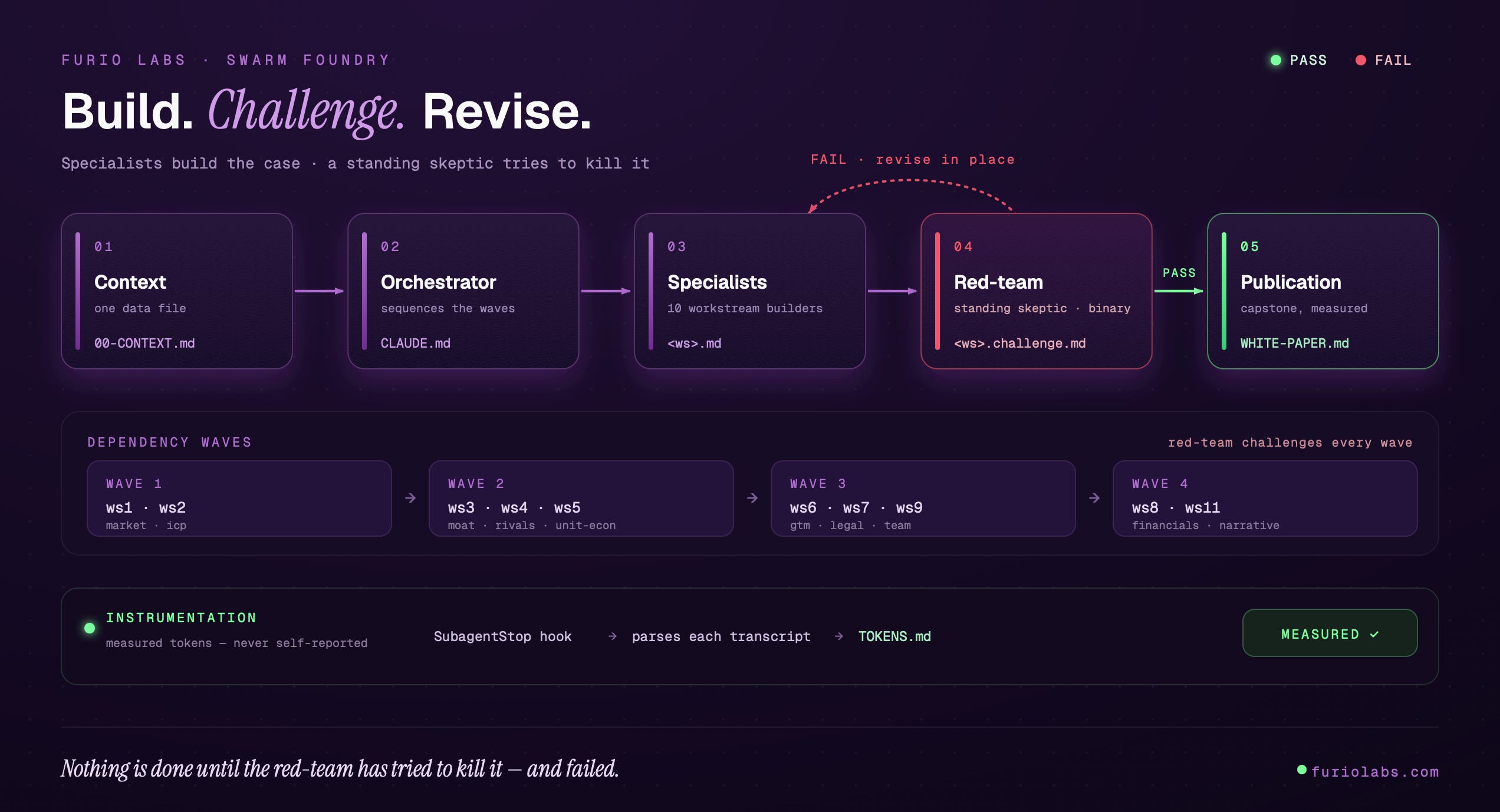
Construí un scaffold (o template) .claude/ drop-in: tú pones la idea y los hechos en un solo archivo de contexto (00-context.md), y 10 agentes especialistas arman el caso completo, cada uno tomando su dominio de ese archivo. Útil pero hasta acá: un generador más.
Cuándo realmente toma forma es a partir de cada entregable: un red-team que tiene permiso de matar completamente el caso (cuestionando cada assumption de los pasos previos). No un revisor que sugiere mejoras — es un escéptico con poder de veto que emite un veredicto binario. PASS o FAIL. Si es FAIL, el trabajo no avanza: vuelve atrás a corregirse en su lugar. Solo cuando pasa, sigue hacia la publicación (el último paso).
Las reglas que hicieron que el resultado fuera honesto y no otro PDF bonito:
→ Ningún agente inventa evidencia. Cada cifra va con su fuente y su fecha, o queda marcada [ASSUMPTION] / [NEEDS HUMAN INPUT]. Una afirmación sin fuente presentada como hecho es FAIL automático.
→ Hay seis Human Gates que respondo yo. Los agentes tienen prohibido adivinarlos. La máquina no decide lo que solo el founder sabe.
→ El escéptico juzga cada re-revisión en frío, sin anclarse en su crítica anterior — para que no exista el teatro de “ya lo arreglé, dame el PASS”.
→ Los tokens se miden del transcript real de cada agente, no se auto-reportan (estoy trabajando en una versión para llevarlos directo a Langfuse, soon).
NOTA honesta: esto consume del orden de 7x los tokens de un solo hilo. No es para una pregunta rápida. Tarda un poco pero vale la pena la inversion si estas comparando con el entregable de una consultora o agencia. Es para cuando quires poner plata, tiempo o reputación detrás de una hipótesis.
Repeat until…
Acá está lo que más me sorprendió. Cuando “dibujé la arquitectura”, me di cuenta de que el valor no vive en ninguno de los agentes individuales. Vive en flujo completo.
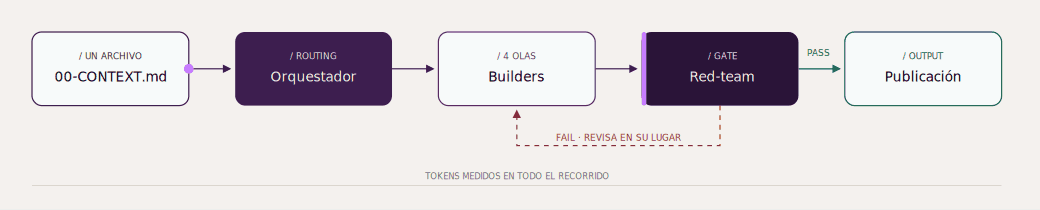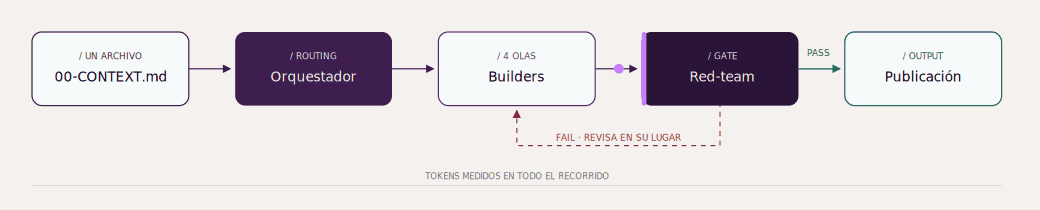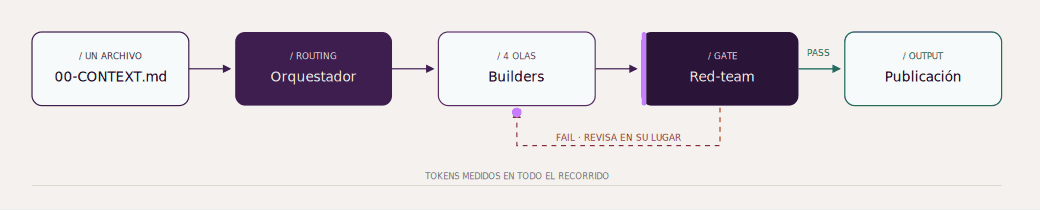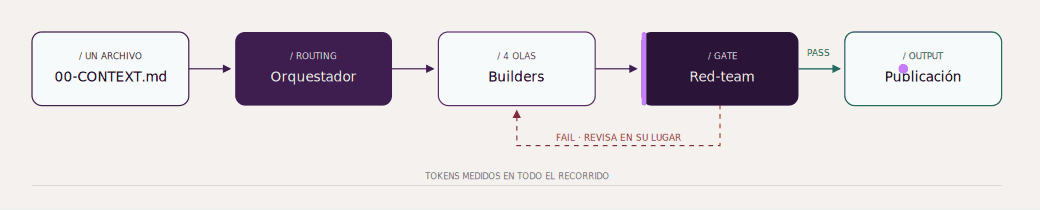
El loop adversarial: construir → desafiar → corregir, con tokens medidos del transcript en todo el recorrido.
Esa flecha de FAIL que vuelve hacia atrás es la tesis entera del experimento. En un generador normal, el output sale en línea recta: contexto → texto → listo. Acá no existe la línea recta. Existe un loop adversarial: nada se considera terminado hasta que el escéptico intentó matarlo y no pudo, o el builder dejó por escrito su rebuttal.
Este flujo es portable. El loop “construir → desafiar → corregir → medir” no tiene nada de específico de un business case. Es un patrón. Si cambias los .md puedes usarlo para cualquier caso de uso.
Validar: es la mitad más fácil
Si el patrón es portable, la pregunta interesante no es “¿sirve para business cases?”. Es ¿Dónde mas podríamos usarlo?
→ Un architecture review donde el red-team busca el punto único de falla que el diseñador no quiere ver.
→ Un security review donde el escéptico asume mala fe en cada supuesto.
→ Un go-to-market donde alguien tiene que sostener, con fuentes, por qué el canal no va a escalar.
→ Cualquier decisión donde el costo de equivocarse es alto y el sesgo de confirmación es mayor.
El scaffold hoy está pensado para el business case y es domain-agnostic — fintech, insurtech, minería, lo que cargues en el contexto. Pero la oportunidad real es tratar el red-team gate como una primitiva reutilizable para cualquier revisión donde quieras que la IA te incomode, no que te aplauda.
Aprendizajes clave
El experimento no me dio un casos “mejores” en el sentido de más impresionante (lo probé con assumptions de varias startups con las que colaboro). Me dio casos más “chicos” y más verdaderos. El escéptico mató afirmaciones que yo habría defendido en una reunión, y me obligó a reemplazar números cómodos por fuentes reales o por un honesto [NEEDS HUMAN INPUT]. Un número real más pequeño le gana a uno inventado impresionante — siempre.
El repo está abierto (y esta evolucionando). 👉 Swarm Foundry
Why god, why?…
En Furio Labs estamos desarrollando Market Swarm un conjunto de agentes de IA que trabajan para producir inteligencia de mercado accionable. No es un chatbot. Es una cadena de agentes especializados que extraen datos primarios de fuentes regulatorias e industria, cruzan fuentes, calculan TAMs y generan un entregable completo — sin intervención humana de investigación. Que pueden ser integrada los procesos de research, lanzamiento de productos, seguimiento regulatorio, análisis de competidores, etc. Y estábamos buscando una forma de hacer challenge a nuestras propias hipótesis y assumptions. ¿Que mejor que compartir esa herramienta y que el experimento (y conocimiento) se siga expandiendo?