
FinOps + Claude: finding the money leaks your rules can't see
Building a cloud-cost CLI that turns an unnavigable bill into a ranked list of leaks — and wiring Claude Haiku in to catch what the rules miss.

A few months ago we sat down with a company — mid-sized, the kind that runs its operations on a couple dozen cloud workloads and not much patience for dashboards — and they told us, almost casually, that their cloud spend had doubled in eight months. Nobody could say which workloads had grown. Nobody could say which ones could be turned off. The bill was paid; the invoices were filed; the spend was unattributed.
That’s a common story, and it’s easy to misdiagnose. The tempting explanation is language — the portal is hard to read. But that’s the last-mile problem, not the real one. The real one is that the cost surface itself is unnavigable. Even a fluent, caffeinated engineer opening the portal at the right hour struggles to answer the only question that matters: where is the money leaking, and what do I do about it?
We built finops — a small Python CLI — to answer exactly that. It queries the cloud account, reconciles what the invoice says against what the resources actually cost, ranks the leaks, and hands back one report you can read in five minutes. This is a walkthrough of what it does, how it is structured, and how the AI piece slots into a deterministic pipeline.
What actually makes cloud cost hard
Before any code, it’s worth naming the real problems — because each one maps to something the tool has to do. This is the list we heard, cleaned up:
→ Every cost report is its own maze. The portal makes you re-navigate, re-filter, and re-learn the view every single time. There’s no stable artifact you can hand to someone else.
→ The invoice and the resource-level detail never line up in your head. One number comes from billing; the other is a pile of per-resource line items. Reconciling them by eye is where people give up.
→ You can’t see where the leaks are. You want recommendations grounded in something concrete — the SKU, the kind of resource, the compute tier — not a wall of undifferentiated line items.
→ There’s no way to compare against good practice, or to segment. By customer, by environment, by team. Without segmentation, “spend went up” is a fact you can’t act on.
→ Untagged resources hide in plain sight. If a resource carries no cost-attribution tags, it’s invisible to any allocation you try to do later.
→ And the long tail — orphaned disks, forgotten non-prod, oversized databases — that no checklist ever fully covers.
finops is the answer to that list. It runs once per subscription per month, or over an arbitrary window, and emits three artifacts:
→ An interactive HTML report with filterable tables, severity badges, and a monthly cost heat map — the stable, shareable view the portal never gives you.
→ A Markdown report for pasting into email and chat.
→ An Excel workbook with one sheet per analyzer, for the people who want to filter and pivot themselves.
Plus a data.json cache, so the HTML can be re-rendered without paying for another cloud API call.
The architecture is intentionally boring
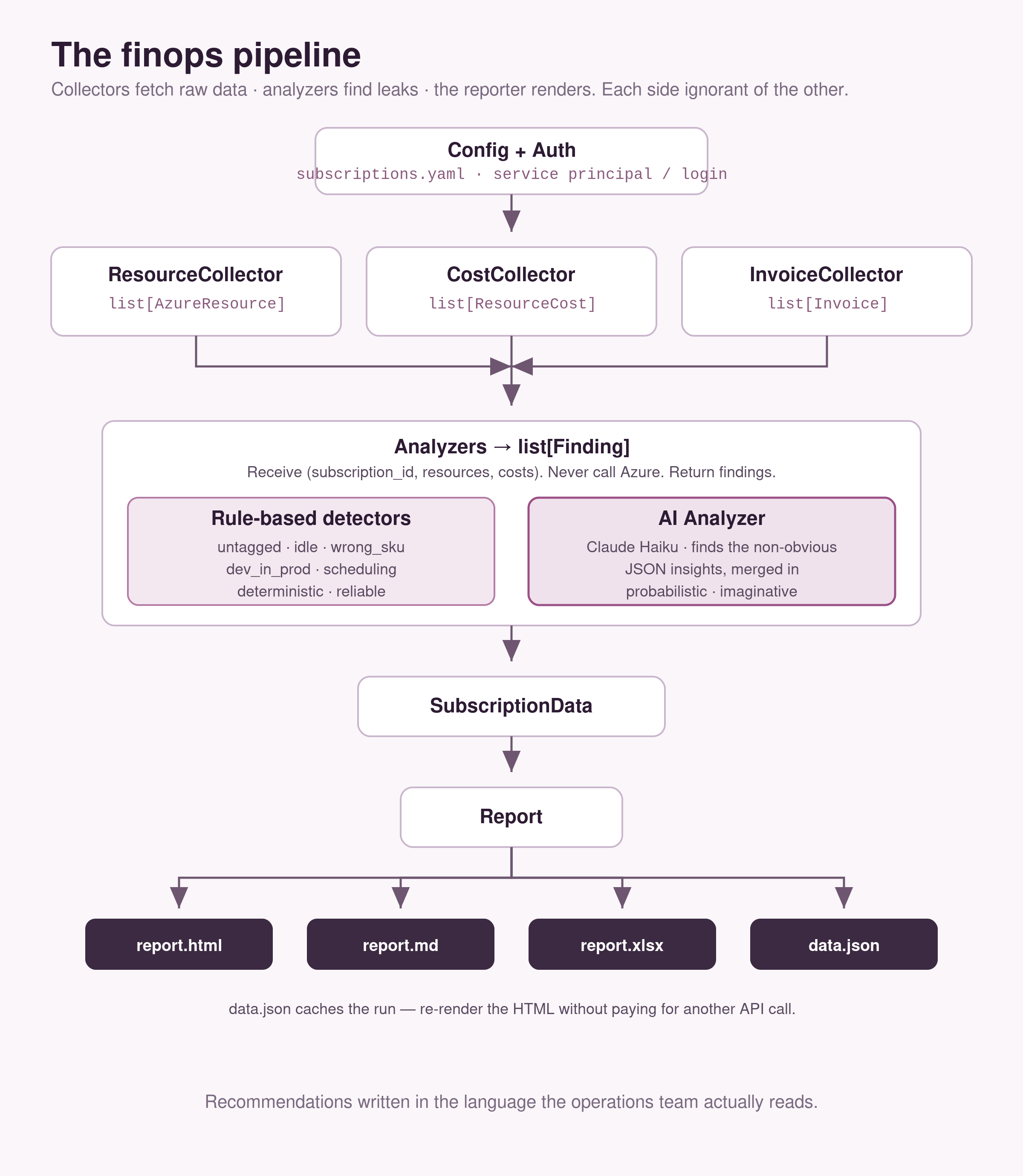
Three collectors fetch the raw data, hand it to a set of analyzers, and a reporter merges everything. This is also where problem #2 gets solved: the InvoiceCollector pulls what billing charged, the CostCollector pulls the per-resource detail, and the report puts them side by side — so the invoice total and the resource-by-resource breakdown finally reconcile in one place instead of in someone’s head.
The collectors do not know about analyzers; the analyzers do not know about the cloud. The analyzers receive (subscription_id, resources, costs) and return list[Finding]. That’s the whole contract.
This boundary is the most important design choice in the project. It means analyzers are stateless and trivially testable — make_resource() and make_cost() builders in the test suite are usually enough to construct any scenario. It also means adding a new detector is a fifty-line task, not a five-hundred-line one.
The rule-based detectors
Five analyzers ship today, each looking for one specific pathology — and between them they cover problems #3, #4, and #5 directly:
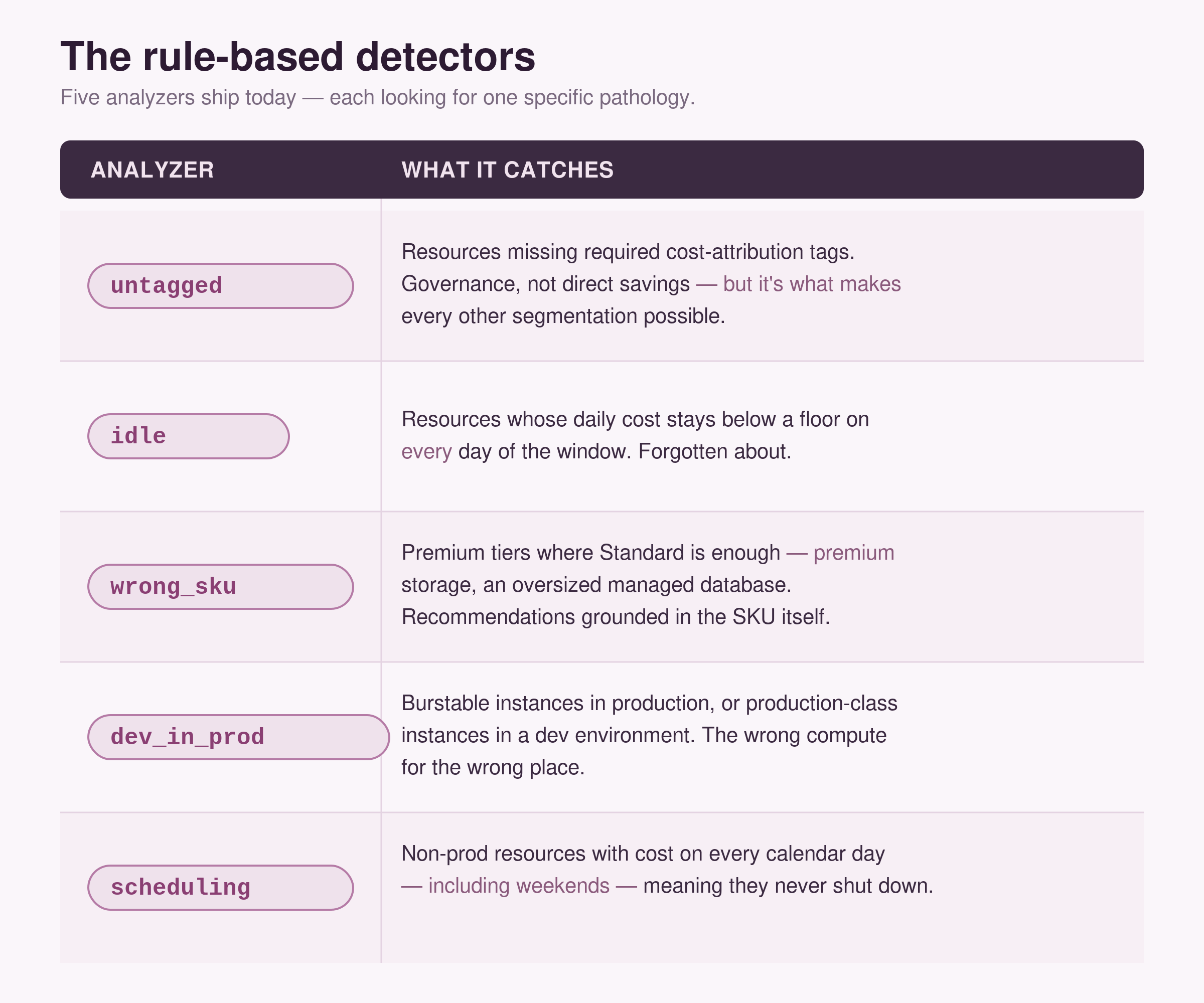
Notice what the findings are keyed on: SKU, resource kind, compute tier, environment tag. That’s problem #3 answered — the recommendation isn’t “spend is high,” it’s “this specific Premium disk should be Standard, saving roughly $X/month.” And because everything carries an environment tag and rolls up per subscription, you get problem #4 for free: segment by customer (one subscription each) and by environment (prod vs dev vs staging).
Each finding carries a Severity (an IntEnum, so sorted(..., reverse=True) puts CRITICAL first), an estimated monthly savings in USD, and a recommendation. The reporter aggregates by subscription, sums the savings, and renders.
In this particular account, the rule-based pass already explained a good chunk of the doubling: a non-prod environment that had quietly been running 24/7 for months, and two oversized databases nobody remembered provisioning. Boring leaks. Boring is good — boring is recoverable.
Where Claude comes in
That covers the problems you can name. It does not cover problem #6 — the long tail, the ones you don’t know to look for. A subscription might have five scale sets that, taken together, suggest a misconfigured autoscaler — no single resource is “idle” or “wrong SKU,” but the shape of the inventory is off. That is the kind of thing a language model is good at.
So we added an AiAnalyzer that runs after the deterministic ones. It builds a prompt containing:
→ The subscription name and total cost over the window. → A count of resources by type. → The top fifteen costliest resources with their SKU, tier, environment tag, and resource group. → The monthly cost trend over the analyzed window. → The categories — not the bodies — of findings the rule-based analyzers already raised, so Claude does not duplicate them.
It sends that to Claude Haiku 4.5, asks for a JSON array of insights, and merges the result into the report under an “AI Insights” section. Haiku was the right choice here: the prompts are one or two kilobytes, the latency budget is “before the engineer’s coffee is cold,” and the cost per subscription is negligible compared to the bills we are auditing.
The schema we ask for:
[
{
"title": "título corto en español",
"category": "ResourceAnalysis|CostAnomaly|Recommendation|MoneyLeak",
"detail": "explicación detallada en español",
"estimated_monthly_savings_usd": 0.0,
"confidence": "high|medium|low"
}
]
The output is in Spanish — same as the rule-based recommendations. That’s the last-mile touch: once the hard part (navigation, reconciliation, ranking) is done, handing the answer to the team in the language they actually read is what gets it acted on. A feature, not the thesis.
The parsing-hardening story
Wiring this up sounds simple. It wasn’t. Two things bit us in the first week of running it against real subscriptions.
One: the model ignores “no markdown” instructions when emitting JSON. Our prompt said responde ÚNICAMENTE con un array JSON válido and sin texto adicional, and Haiku still wrapped the array in fenced code blocks part of the time. The lesson: do not fight the model on output formatting. Just write a parser that handles fences. Ours uses raw.find("[") and raw.rfind("]") to extract whatever is between the brackets, regardless of what surrounds them.
Two: structured output blows past small max_tokens caps. We initially set max_tokens=1024, which is fine for a chat response but tight for a JSON array of detailed Spanish recommendations. When Haiku ran out of tokens mid-array, the response had an opening [ but no closing ]. Our parser then raised:
No JSON array in response: '```json\n[\n {\n "title":
"Consumo excesivo de máquinas virtuales escaladas", ...
— and the error message itself was misleading, because it only printed the first two hundred characters, hiding the fact that the real problem was truncation at token 1024, not a missing array.
The fix is small and a little embarrassing in retrospect:
msg = self._client.messages.create(
model=self._model,
max_tokens=self._max_tokens, # default 4096, env-overridable
messages=[{"role": "user", "content": prompt}],
)
raw = msg.content[0].text
if getattr(msg, "stop_reason", None) == "max_tokens":
raise ValueError(
f"AI response truncated at {self._max_tokens} tokens; "
f"raise FINOPS_AI_MAX_TOKENS. Partial: {raw[:200]!r}"
)
Two changes:
Bump the default token budget from 1024 to 4096. Haiku 4.5 supports far more output than that; 4096 is generous for ten dense insights and cheap.
Check
stop_reasonbefore trying to parse. When the model stopped because it hit the cap, raise a clear truncation error that names the env var to raise. When it stopped because it was finished, parse normally.
The general principle: when you wire a language model into a structured-output pipeline, the parser should distinguish between “the model produced something I don’t understand” and “the model didn’t finish.” Those have different remedies, and treating them the same makes every truncation bug look like a model regression.
We backed both changes with unit tests using MagicMock clients, including a test that mocks stop_reason="max_tokens" and asserts the right error is raised. Mocking the Anthropic client at the constructor boundary is enough; we do not need a fake transport.
Key takeaways
The technically interesting part of this project is not the analyzers. It is the boundary between deterministic and probabilistic detection.
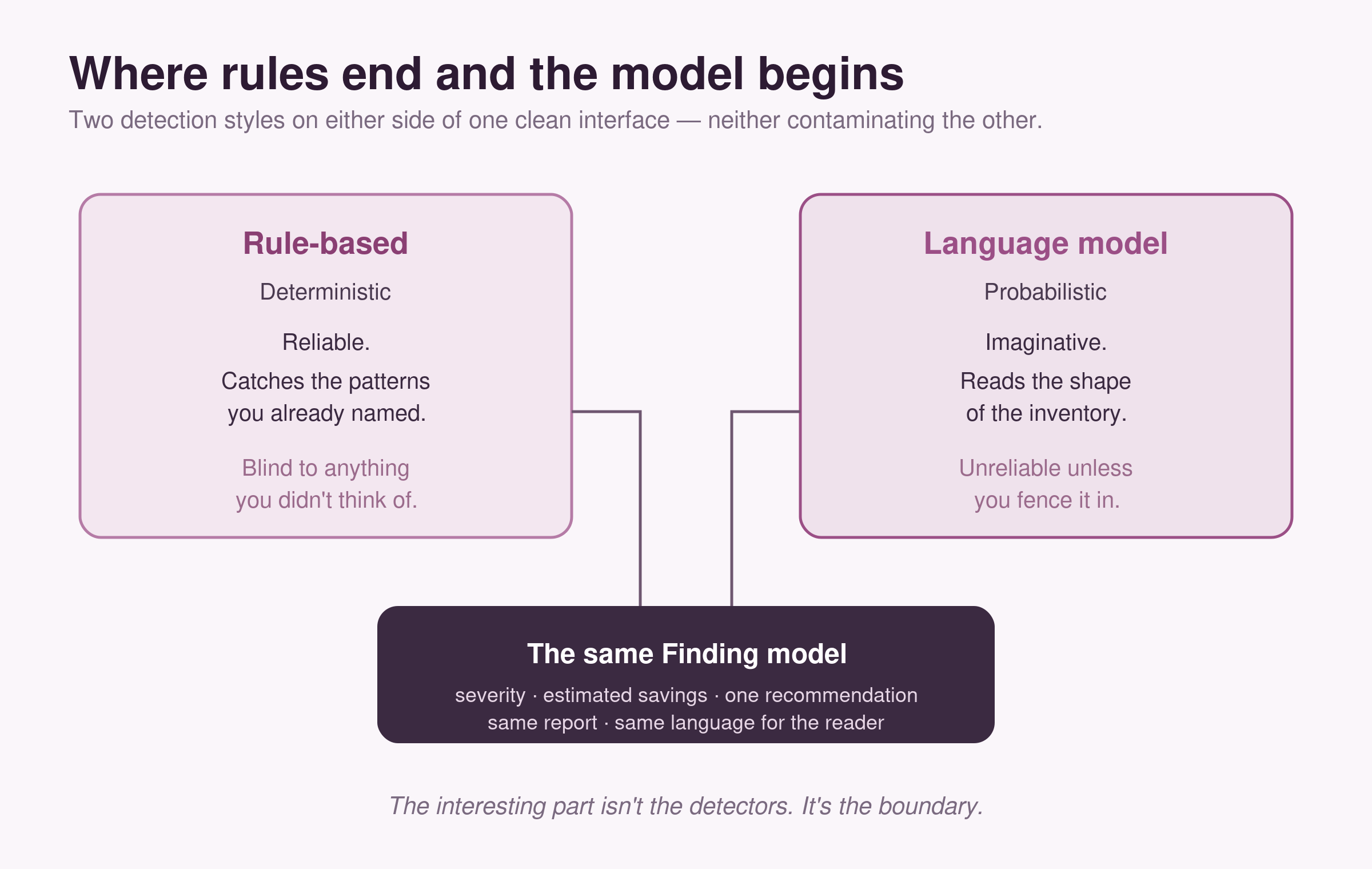
Rule-based code is reliable but blind to anything you did not think of. Language models are imaginative but unreliable. Put them on either side of a clean interface — same Finding model, same recommendations, same report — and each does what it is good at without contaminating the other.
That is the bet, anyway. Six months in, the reports are short, the leaks are ranked, and the invoice finally reconciles against the resource detail on a single page. The company that couldn’t explain its doubled bill now gets a two-page answer every month — navigable, segmented, and in the language the people paying the bill actually read.
We will take it.
Repository is available as part of Furio Labs portfolio and you can download and use and/or contribute in the repo:
Enjoy and share.